All Tags
AWS
ai
algorithm-design
architecture
browser
cloud
cloud-efficiency
cloud-principles
cost-reduction
data-centric
data-compression
data-processing
deployment
design
documentation
edge-computing
email-sharing
energy-efficiency
energy-footprint
enterprise-optimization
green-ai
hardware
libraries
llm
locality
machine-learning
maintainability
management
measured
microservices
migration
mobile
model-optimization
model-training
multi-objective
network-traffic
parameter-tuning
performance
queries
rebuilding
scaling
services
storage-optimization
strategies
tabs
template
testing
workloads
Tactic: Use Input Quantization
Tactic sort:
Awesome Tactic
Type: Architectural Tactic
Category: green-ml-enabled-systems
Title
Use Input Quantization
Description
Input quantization in machine learning refers to the process of converting data to a smaller precision (e.g., reduce number of bits to represent data). For example, Abreu et al (2022) investigated different input widths (bits) and found that 10-bit precision is sufficient for achieving accuracy in models, and that increasing the number of bits does not contribute to accuracy. Therefore, using higher precision is a waste of resources. Additionally, using precise data values through input quantization can even have a positive impact on the machine learning model by reducing overfitting.
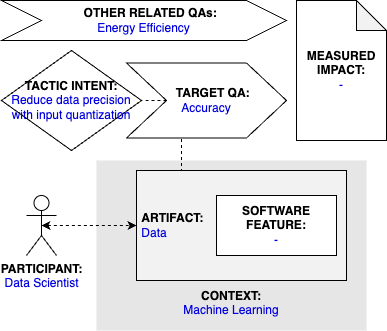
Participant
Data Scientist
Related software artifact
Data
Context
Machine Learning
Software feature
< unknown >
Tactic intent
Improve accuracy (and energy efficiency) by reducing data precision with input quantization
Target quality attribute
Accuracy
Other related quality attributes
Energy Efficiency
Measured impact
< unknown >
Source
Brunno Abreu, Mateus Grellert, and Sergio Bampi. 2022. A Framework for Designing Power-Efficient Inference Accelerators in Tree-Based Learning Applications. Engineering Applications of Artificial Intelligence 109 (2022), 104638. [DOI](https://doi.org/10.1016/j.engappai.2021.104638); Minsu Kim, Walid Saad, Mohammad Mozaffari, and Merouane Debbah. 2021. On the Tradeoff between Energy, Precision, and Accuracy in Federated Quantized Neural Networks. In ICC 2022 - IEEE International Conference on Communications. 2194–2199. [DOI](https://doi.org/10.1109/ICC45855.2022.9838362)Graphical representation